코루틴?
하나의 개별적인 작업을 루틴(routine)이라고 부르는데 코루틴이란 여러 개의 루틴들이 협력(co)한다는 의미로 만들어진 합성어.
프로세스와 스레드
하나의 프로그램이 실행되면 프로세스가 시작되는데 프로세스는 실행되는 메모리, 스택, 열린 파일 등을 모두 포함하기 때문에 프로세스 간 문맥 교환을 할때 많은 비용이 든다.
반면, 스레드는 자신의 스택만 독립적으로 가지고 나머지는 스레드끼리 공유하므로 문맥 교환 비용이 낮아 프로그래밍에서 많이 사용된다.
스레드
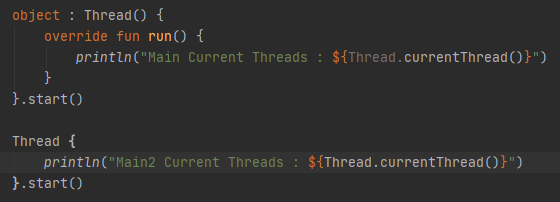
스레드 루틴을 만드려면 Thread 클래스를 상속받거나 Runnable 인터페이스를 구현하여 사용한다.

이런식으로 사용이 가능하며, 익명 클래스를 사용하면 다음과 같이 사용이 가능하다.
스레드 풀 사용하기
몇 개의 스레드를 먼저 만들어 놓고 필요에 따라 재사용하도록 설계할 수 있다.
newFixedThreadPool()로 스레드를 인자의 수 만큼 만들고 작업을 수행할 때 여기서 재사용 가능한 스레드를 고르게 한다.
val service: ExecutorService = Executors.newFixedThreadPool(8)
코루틴의 기본 개념
프로세스나 스레드는 해당 작업을 중단하고 다른 루틴을 실행하기 위해 문맥 교환을 시도할 때 많은 비용이 든다. 코루틴은 비용이 많이 드는 문맥 교환 없이 해당 루틴을 일시 중단해서 이러한 비용을 줄일 수 있다.

코루틴의 기본적인 예제로, GlobalScope,launch { ... } 부분이 코루틴 코드이다.
main에서는 hello를 출력하고 2초 후에 종료되며, 코루틴 코드는 메인 스레드와 분리되어 백그라운드에서 1초 뒤에 실행이 된다. 따라서, hello가 출력되고 1초 후에 world가 출력되고 그 1초 후에 메인 스레드가 종료되게 되는 것이다.
코루틴을 사용하였으므로 메인 스레드와 별도로 실행되는 넌블로킹 코드가 된다.
코루틴에서 사용되는 함수는 suspend()로 선언된 지연 함수여야 코루틴 기능을 사용할 수 있다.
async 사용
async도 새로운 코루틴을 실행할 수 있는데 launch와 다른 점은 Deferred<T>를 통해 결괏값을 반환한다는 것이다.
이때 지연된 결괏값을 받기 위해 await()를 사용할 수 있다.

이와 같이 사용하는 경우, combined 변수에서 one, two 의 스레드가 모두 완료 된 후에 해당 값을 합쳐서 저장하기 때문에 two 에서 호출하는 doWork2가 완료되는 3초 후에 값을 가져와 combined 변수를 출력하게 된다.
시작 지점 속성
launch, async는 start 매개변수를 사용하여 시작하는 타이밍을 지정할 수 있다.
- DEFAULT : 즉시 시작
- LAZY : 코루틴을 느리게 시작. start() 나 await() 등으로 시작
- ATOMIC : 최적화된 방법으로 시작
- UNDISPATCHED : 분산 처리 방법으로 시작
val sam = async(start = CoroutineStart.LAZY) { doWork1() }
...
sam.start() // sam.await()
runBlocking
runBlocking은 새로운 코루틴을 실행하고 완료되기 전까지 현재 스레드를 블로킹한다.
위의 예제들에서 코루틴이 끝나기 전에 메인 스레드가 끝나는 것을 방지하기 위해서 메인 스레드에서 delay나 readLine을 사용했는데, main 함수에 runBlocking을 사용함으로써 코루틴이 완료될 때 까지 메인 스레드를 잡아둘 수 있다.

이처럼 sleep을 사용하지 않아도 world를 출력할 때 까지 메인 스레드는 종료되지 않는다.
이는 클래스 내 멤버 메서드에서도 사용이 가능하다.
join() 함수
코루틴의 작업이 완료되는 것을 기다리게 하려면 join 함수를 사용하면 된다.

join을 사용하면 명시적으로 코루틴이 완료되기를 기다린다. 취소할 경우 cancel() 함수를 사용하면 된다.
코루틴
코루틴은 항상 특정 문맥에서 실행된다. 이때 어떤 문맥에서 실행할지는 디스패처(Dispatcher)가 결정한다.
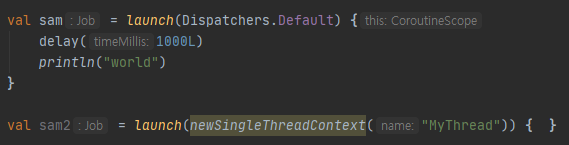
이처럼 launch의 매개변수로 사용하게 되는데, Dispatchers의 경우 4 종류로 설정이 가능하다.
- Dispatchers.Unconfined : 메인 스레드에서 작업. 권장하지 않는 옵션
- Dispatchers.Default : 디스패처의 기본값
- Dispatchers.IO : 입출력 위주의 동작을 하는 코드에 적합한 공유된 풀. 블로킹 동작이 많은 파일이나 소켓 I/O에 적합
- newSingleThreadContext : 사용자가 직접 새 스레드 풀을 만들어서 사용. 새 스레드를 만들기 때문에 비용이 많이 들고, 더 이상 필요하지 않으면 해제하거나 종료해야한다.
기본동작 제어
- repeat() 함수를 이용하여 반복하는 코드를 작성할 수 있다.
- cancel() 함수를 이용하면 함수를 종료시킬 수 있다.
- cancelAndJoin() 함수를 이용하면 작업을 취소하고 완료될 때 까지 기다린다.
- withContext(NonCancellable) { ... } 사용하여 finally 함수 실행을 보장할 수 있다. finally 블록에 시간이 걸리는 작업이나 지연 함수가 사용될 경우 실행을 보장할 수 없다. 따라서, withContext 문맥에서 try-catch-finally 블록이 작동하도록 하여 이를 보장한다.
- withTimeout(time) 함수를 이용하여 일정 실행 시간 뒤에 코루틴을 취소할 수 있도록 할 수 있다.
채널
채널(Channel)은 자료를 서로 주고받기 위해 약속된 일종의 통로 역할을 한다.
채널을 구현할 때는 SendChannel과 ReceiveChannel 인터페이스를 이용해 값들의 스트림을 전송하는 방법을 제공한다. 실제 전송에는 지연함수의 send()와 receive() 함수를 사용한다.

launch 블록에서 send 한 값을 receive에서 받아와 읽을 수 있으며, 채널은 일반 큐와는 다르게 전달요소가 없으면 close를 통해 채널을 닫을 수 있다.
또한, 채널을 생성할 때, 소괄호 안에 Int형 값을 넣어주면 그만큼 버퍼 크기가 설정이 된다.
produce
produce는 채널이 붙어있는 코루틴으로 생산자 측면의 코드를 쉽게 구성할 수 있다. 채널에 값을 보내면 생산자로 볼 수 있고 소비자는 consumeEach 함수를 확장해 for문을 대신 해서 저장된 요소를 소비한다.

producer는 값을 생산하고 ReceiveChannel을 반환한다. 따라서 result에서 ReceiveChannel의 확장 함수인 consumeEach를 사용하여 각 요소를 처리한다.
select
select를 사용하면 각 채널의 실행 시간에 따라 달라지는 결과 값을 받아올 수 있다.

result 에서 사용되는 select를 통해 result 값은 routine1,2 중 먼저 수행된 것을 받아서 저장되게 된다.
동기화 기법
synchronized 메서드와 블록
Kotlin에서 synchronized를 메서드에 사용하려면 @Synchronized 애노테이션 표기법으로 사용해야 한다.
@Synchronized fun synchronizedMethod() {
println("sync = ${Thread.currentTread()}")
}
volatile
자바의 volatile도 Kotlin에서 같은 방법으로 사용할 수 있다. 보통 변수는 성능 때문에 데이터를 캐시에 넣어두고 작업하는데 이때 여러 스레드로부터 값을 읽거나 쓰면 데이터가 일치하지 않고 깨지게 된다. 이것을 방지하기 위해 데이터를 캐시에 넣지 않도록 volatile 키워드와 함께 변수를 선언할 수 있다.
한 스레드에서 volatile 변수 값을 읽고 쓰고, 다른 스레드에서는 오직 volatile 변수 값을 읽기만 하는 경우, 읽는 스레드에서는 volatile 변수가 가장 최근에 쓰여졌다는 것을 보장한다.
원자 변수
원자 변수란 특정 변수의 증가나 감소, 더하기나 빼기가 기계어 명령으로 수행되는 것을 말하며 해당 연산이 수행되는 도중에는 누구도 방해자히 못하기 때문에 값의 무결성을 보장할 수 있게 된다.
순차적 프로그램에서는 문제가 없으나 많은 수의 독립적인 루틴이 하나의 변수를 공유하면 언제든 코드가 중단될 수 있다.
원자 변수를 사용하면 변수의 연산 부분을 cpu의 기계어 명령 하나로 컴파일 하게 되기 때문에 무결성을 보장한다.
var counter = AtomicInteger(0) // 원자 변수로 초기화
...
counter.incrementAndGet() // 원자 변수의 멤버 메서드를 사용해 값 증가
...
println("Count = ${counter.get()}") // 값 읽기
원자 변수는 위와 같이 선언 및 사용할 수 있다.
상호 배제
상호 배제는 코드가 임계 구역에 있는 경우 절대로 동시성이 일어나지 않게 하고 하나의 루틴만 접근하는 것을 보장한다.
Kotlin에서는 Mutex의 lock과 unlock을 통해 임계 구역을 만들 수 있다.
val mutex = Mutex()
...
mutex.lock()
... // 보호하고자 하는 임계 구역 코드
mutex.unlock()
...
이와 같이 임계 구역을 만들 수 있으며, tryLock()을 통해 임계 구역이 잠겨있는지 확인이 가능하고, holdsLock()을 통해 소유자에 의한 잠금인지 확인이 가능하다.
람다식 withLock을 사용하면 mutex.lock() try { ... } finally { mutex.unlock() } 과 같은 패턴을 쉽게 사용할 수 있다.
mutex.withLock {
... // 임계 구역 코드
}
'Language > Kotlin' 카테고리의 다른 글
| [Android] Fragment에서 데이터를 전달하는 3가지 방법. (0) | 2022.08.26 |
|---|---|
| [Android] Coroutine Flow를 사용하여 API를 호출해보자. (2) | 2022.03.19 |
| [Kotlin] 9장. 표준 함수와 파일 입출력 (0) | 2020.07.14 |
| [Kotlin] 9장. 컬렉션 (0) | 2020.07.10 |
| [Kotlin] 8장. 제네릭과 배열 2 - 배열 (0) | 2020.07.08 |


