약 2년 전, Compose를 처음으로 공부하면서 Side Effect에 대해서 공부하면서 글을 작성했었다.
2022.06.08 - [Android/Jetpack Compose] - [Jetpack] Compose 사용하기 - 2. Side Effect와 Coroutine 1
2022.06.09 - [Android/Jetpack Compose] - [Jetpack] Compose 사용하기 - 2. Side Effect와 Coroutine 2
공부하던 당시 보고 있던 책의 순서에 따라 공부하면서 작성했었는데, 실무에 적용하기 전 이론으로만 공부했던 부분이라 정확히 어떻게 사용하고, 사용할 수 있는지에 대해 이해를 하지 못한 상태로 작성했었다.
최근 실무를 진행하면서 recomposition 관련해서 자주 생각하게 되고, 이것을 개선할 수 있는 방법 중 Side Effect를 사용하는 것이 기본적이라고 생각이 들었다.
다시 한번 개념을 복습할 겸 Side Effect 관련한 API를 다시 정리해보고자 한다.
LaunchedEffect를 시작으로 연관 있는 순서대로 글을 작성해 보도록 하겠다.
근본적이고, 개념적인 부분은 이전 글에 정리가 되어있긴 하니 그런 부분은 건너뛰도록 하겠다.
위에 언급한대로, LaunchedEffect부터 시작하도록 하자.
@Composable
@NonRestartableComposable
@OptIn(InternalComposeApi::class)
fun LaunchedEffect(
key1: Any?,
// vararg keys: Any?,
block: suspend CoroutineScope.() -> Unit
) {
val applyContext = currentComposer.applyCoroutineContext
remember(key1) { LaunchedEffectImpl(applyContext, block) }
}
LaunchedEffect는 Key 값(들)이 변경될 때마다 이하 block 영역을 비동기로 수행하게 된다.
여기서 중요한 것은 key 값과 block에 선언한 함수에 따라서 다양하게 사용이 가능하다는 점이다.
첫 번째로 자주 사용하는 방식으로는
LaunchedEffect(key1 = Unit, block = {
...
})
이처럼 key 값에 Unit을 넣어줘서 해당 함수가 반드시 한번만 호출되도록 구현이 가능하다.
그냥 Compose 함수 내부에 작성하는 것과 LaunchedEffect에 Unit으로 작성하는 것과 무엇이 다른데?라고 생각할 수 있지만 큰 차이가 존재한다.
비동기로 수행한다는 것도 있지만 필자가 생각했을 때 가장 큰 부분은 recomposition의 차이라고 생각한다.
Compose 함수 내부에 작성하는 경우 해당 UI가 다시 그려지는 경우 반드시 전체적으로 다시 수행되게 되며 LaunchedEffect 안에 들어있는 block은 recomposition이 발생해도 다시 수행되지 않는다.
즉, recomposition이 자주 일어날 가능성이 있는 Compose 함수 안에서는 데이터의 변경 및 연산이 이루어지는 부분이 재 실행되지 않길 원한다면 LaunchedEffect와 같이 실행을 제한할 수 있는 영역에서 수행해 주는 것이 좋다.
다음으로 사용하는 방법은 LaunchedEffect의 block 안에 snapshotFlow를 사용하는 방법이다.
LaunchedEffect(key1 = Unit, block = {
snapshotFlow { isChanged.value }
.collect {
...
}
})
snapshowFlow가 뭔지는 모르겠지만 우선 위의 내용을 생각해보았을 때, 해당 Compose 함수가 실행될 때 최초 한번 호출이 되며 그때 block 영역이 수행될 것 같다. 그런데 isChanged의 데이터를 보고 뭔가 할 것 같다.라고 생각이 들 것이다.
그럼 그 상태에서 snapshotFlow의 설명을 확인해보자.
Create a Flow from observable Snapshot state. (e.g. state holders returned by mutableStateOf.) snapshotFlow creates a Flow that runs block when collected and emits the result, recording any snapshot state that was accessed. While collection continues, if a new Snapshot is applied that changes state accessed by block, the flow will run block again, re-recording the snapshot state that was accessed. If the result of block is not equal to the previous result, the flow will emit that new result. (This behavior is similar to that of Flow.distinctUntilChanged.) Collection will continue indefinitely unless it is explicitly cancelled or limited by the use of other Flow operators.
번역해 보면 알 수 있겠지만, 간단하게 요약해 보자면 지정한 데이터에 대해 관찰이 가능하도록 flow를 만들고, 관찰 중인 데이터의 변경을 기록한다고 한다.
즉, 위의 함수는 compose 함수가 실행될 때 최초 한 번만 호출이 되는데, isChanged.value의 변화를 탐지할 수 있는 snapshotFlow를 만들고 이 데이터가 변경될 때마다 collect 이하의 부분을 실행한다.
즉, block 부분을 실행한다는 관점으로 보았을 때
LaunchedEffect(key1 = isChanged.value, block = {}) 와 위의 snapshotFlow는 동일한 동작을 하게 되는 것이다.
하지만 LaunchedEffect는 key값이 변경될 때 마다 block이 "실행" 되는 것이고, snapshotFlow는 최초 한번 실행될 때 isChanged 값을 "관찰"하도록 하고, 그 데이터가 변경될 때 block을 실행되게 하는 것이므로 동작은 같으나 동작을 수행하기까지의 동작과 범위가 다르다고 생각하면 된다.
다음으로는 LaunchedEffect와 비슷하게 동작을 하는 DisposableEffect이다.
@Composable
@NonRestartableComposable
fun DisposableEffect(
key1: Any?,
// vararg keys: Any?,
effect: DisposableEffectScope.() -> DisposableEffectResult
) {
remember(key1) { DisposableEffectImpl(effect) }
}
LaunchedEffect와 비슷하게 보이지만, block 대신 effect으로 되어있는 DisposableEffectScope가 존재한다.
해당 부분은 block과 동일하게 사용하면 되지만, DisposableEffectResult가 onDispose를 포함하고 있기 때문에 해당 함수를 override 해서 반드시 선언해 주어야 사용이 가능하다.
DisposableEffect(key1 = Unit, effect = {
... // 1
onDispose {
... // 2
}
})
이런 식으로 말이다.
DisposableEffect는 기본적으로 LaunchedEffect와 비슷하게 사용이 된다.
즉, Key 값(들)이 변경될 때마다 이하 effect 영역을 비동기로 수행하게 된다.
Unit으로 key 값을 선언하면 최초 한 번에 선언되는 것이고, isChanged와 같은 값을 key 값으로 선언되면 key 값이 변경될 때마다 이하의 effect 부분을 수행한다.
하지만 onDispose를 선언하고 그 안에 함수를 구현할 수 있다는 점이 차이점으로 볼 수 있는데, 함수 이름을 보면 알 수 있듯이 해당 DisposableEffect가 취소되거나 해당 컴포즈 함수를 떠나게 되면 반드시 호출 onDispose 함수가 호출되게 된다.
따라서, 위의 Unit을 key값으로 가지고 있는 DisposableEffect의 경우 최초 한번 1번 영역을 실행하고, 해당 컴포즈 함수를 떠날 때 2번 영역을 한번 실행하게 된다.
key값이 Unit이기 때문에 recomposition이 수행되지 않기 때문에 1번 영역과 2번 영역이 반복해서 호출될 수는 없다.
DisposableEffect(key1 = isChanged.value, effect = {
... // 3
onDispose {
... // 4
}
})
하지만 위와 같이 선언이 되어있을 경우, 최초 접근 시 3번 영역 호출, isChanged.value 값이 변경되면 4번 호출 -> 3번 호출 순서대로 해당 DisposableEffect가 실행되기 전 이전에 수행된 부분을 dispose 시키는 로직이 추가가 된다.

해당 Effect 내부에서 로그를 찍어보면 이런 형태로 나오게 된다.
LaunchedEffect와 DisposableEffect는 key값에 따라서 이하 함수를 수행시킨다는 것은 동일하게 생각될 수 있다.
그렇다면 반대로 key값을 떠나서 화면이 다시 그려질 때마다, recomposition이 발생할 때 마다 함수를 수행시키려면 어떻게 해야 할까?라는 의문이 들 수 있다.
그럴 때 사용할 수 있는 것이 SideEffect이다.
@Composable
@NonRestartableComposable
@ExplicitGroupsComposable
@OptIn(InternalComposeApi::class)
fun SideEffect(
effect: () -> Unit
) {
currentComposer.recordSideEffect(effect)
}
정말 단순하게 나와있다.
해당 함수의 설명의 끝 부분을 보면 다음과 같이 나와있다.
A SideEffect runs after every recomposition. To launch an ongoing task spanning potentially many recompositions, see LaunchedEffect. To manage an event subscription or other object lifecycle, see DisposableEffect.
SideEffect는 재구성될 때마다 실행된다. 디테일하게 관리하려면 LaunchedEffect 나 DisposableEffect를 사용해라.
라고 말이다.
즉,
SideEffect를 선언하게 되면 effect 영역이 recomposition이 성공적으로 수행된다면 반드시 호출되는 것이다.
필자는 실무에서 해당 sideEffect는 recomposition이 얼마나 자주 일어나는지 확인하기 위해, 그 횟수를 줄이기 위해 로그를 찍어두는 용도로 사용하긴만 했지만 조건만 잘 추가해 준다면 다양한 환경에서 편하게 사용이 가능할 것 같다는 생각이 들었다.
다음으로는 Effect Block 말고, remember를 사용하여 변수에 값을 저장하는 부분에 사용되는 API를 확인해 보자.
그중 첫 번째는 rememberUpdatedState이다.
해당 API의 설명을 보면 다음과 같다.
remember a mutableStateOf and update its value to newValue on each recomposition of the rememberUpdatedState call.
재구성될 때마다 rememberUpdatedState는 새로운 값으로 업데이트한다고 한다.
지금 다시 이 말을 봐도 이해가 되지 않기 때문에 예제를 통해 이해해 보도록 하자.
var textState by remember { mutableStateOf("Default") }
Column(modifier = Modifier.padding(16.dp)) {
TextField(
value = textState,
onValueChange = { change ->
textState = change
}
)
Text("textState : $textState")
}
이와 같이 구현을 하고, TextField에 있는 값을 변경하도록 하자.
TextField에 입력된 값을 textState에 저장하고, 그 저장된 값을 Text Compose 함수를 통해 화면에 보여주도록 되어있다.
그렇다면 이 변경된 textState 값을 다른 함수의 파라미터로 넘겨서 사용하게 된다면 어떻게 될까?
@Composable
fun UpdateRememberExample(
isChanged: MutableState<Boolean>
) {
var textState by remember { mutableStateOf("Default") }
Column(modifier = Modifier.padding(16.dp)) {
TextField(
value = textState,
onValueChange = { change ->
textState = change
isChanged.value = isChanged.value.not()
}
)
Text("textState : $textState")
RememberUpdateTestText(textState)
}
}
@Composable
fun RememberUpdateTestText(text: String) {
var rememberTextBy by remember { mutableStateOf(text) }
val rememberText = remember { mutableStateOf(text) }
val rememberUpdatedText by rememberUpdatedState(text)
var rememberTextByApply by remember { mutableStateOf(text) }
.apply {
value = text
}
Text("text : $text")
Text("rememberTextBy : $rememberTextBy")
Text("rememberText : ${rememberText.value}")
Text("rememberUpdatedText : $rememberUpdatedText")
Text("rememberTextByApply : $rememberTextByApply")
}
여기서 rememberTextByApply 부분을 작성한 이유는, rememberUpdatedState 자체가 저런 식으로 구현이 되어있기 때문에 직관적으로 확인을 위해 넣어두었다. 해당 부분의 결과 값은 rememberUpdatedText와 반드시 일치한다.
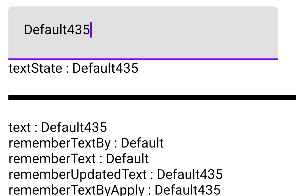
위의 예제의 결과 값은 다음과 같다. default 값으로 "Default"라는 텍스트를 넣어주었고,
이를 변경하였을 때 String타입의 변경된 text를 받았을 때 데이터를 어떻게 가지고 있는지를 확인할 수 있다.
mutable 한 데이터인 textState를 String 타입의 변수로 다른 함수로 전달한다면, 그대로 String 타입으로 사용하는 경우 재구성되면서 새로운 값으로 변경되게 된다.
하지만, 매개변수를 받은 입장에서도 remember를 사용해 변수를 가져오게 된다면, 재구성이 일어나기 전 데이터를 계속해서 가지고 있기 때문에 rememberTextBy, rememberText 두 가지 케이스에서는 변경된 데이터를 가져오지 못한다.
그렇기 때문에, rememberUpdatedState를 사용함으로써 재구성이 일어나는 경우, mutable 한 데이터가 변경되면 그 변경된 값의 최신 값을 가져올 수 있도록 하여 최신 값을 사용할 수 있게 된다.
물론, 이와 같은 예제를 통해 rememberUpdatedState를 보면 사용에 굉장히 제한적이고 그다지 쓸모가 없지 않나? 싶을 수 있다.
하지만, "remember로 저장되는 데이터"와 "재구성 시 데이터의 최신화" 두 가지 관점을 생각해 보았을 때 사용할 수 있는 부분은 상당히 많게 될 것이다.
TextField로 데이터를 변경하고 그 값을 저장해서 그렇지, 실제로는 SideEffect 관련된 block을 선언해 두고 재구성했을 시 별도의 로직을 처리한다고 생각해 보자.
필요한 데이터가 변경되어서 다시 그려지는 게 아니라, 다른 이유로 인해 화면이 다시 그려질 때 어떠한 작업을 수행해야 하고, 그 작업에는 remember로 선언된 변수를 사용해야 한다면 rememberUpdatedState는 해당 작업을 쉽게 수행할 수 있도록 도와줄 것이다.
다음으로는 produceState이다.
@Composable
fun <T> produceState(
initialValue: T,
key1: Any?,
// vararg keys: Any?,
producer: suspend ProduceStateScope<T>.() -> Unit
): State<T> {
val result = remember { mutableStateOf(initialValue) }
LaunchedEffect(key1) {
ProduceStateScopeImpl(result, coroutineContext).producer()
}
return result
}
produceState는 Key 값(들)이 변경될 때마다 이하 producer 영역을 비동기로 수행하게 된다는 면에서는 위에 설명했던 LaunchedEffect 들과 비슷한 모습을 보인다.
또한, producerStateScope는 awaitDispose 함수를 가지고 있는 interface이기 때문에 awaitDispose 함수를 반드시 구현해야 한다는 점에서는 DisposableEffect와도 비슷하다.
하지만 produceState의 차이점은 initValue가 존재한다는 점이다.
produceState는 key값이 변화할 때 마다 producer block이 시작되며, 이전에 작업 중이던 producer block이 있다면 이를 취소한다.
여기까지는 기존의 DisposableEffect와 같은데,
이때, 변수에 저장되는 데이터는 key값이 아닌 producer 변수 안에서 initialValue에서 설정한 default 값의 type의 변수를 컨트롤 한 값을 반환하여 저장하게 된다.
또한, producer block이 다시 시작될 때마다 value값은 초기화되는 것이 아니라 이전의 상태에서 나온 결과 값을 병합하여 사용하게 된다.
이게 무슨 말인가 싶을 것이다.
다음의 예제를 확인하면서 다시 이해해 보자.
var isTimer by remember { mutableStateOf(false) }
val timer by produceState(initialValue = 0, key1 = isTimer, producer = {
var job: Job? = null
if (isTimer) {
job = coroutineScope.launch {
while (true) {
delay(1000)
value++
}
}
}
awaitDispose {
job?.cancel()
}
})
Column(horizontalAlignment = Alignment.CenterHorizontally) {
Text("Time : $timer")
Button(onClick = {
isTimer = !isTimer
}) {
Text(if (isTimer) "Stop" else "Start")
}
}
버튼이 하나 있고, 버튼 클릭에 따라서 isTimer라는 값은 true, false가 변경되게 된다
produceState는 default 값으로 0을 가지고 있으며, key값은 isTimer의 값, producer에서는 isTimer가 true일 때 1초당 value를 1씩 증가하는 로직을 가지고 있다. 여기서 value라고 작성된 부분은 initialValue에서 설정한 default값 (0)의 type인 Int를 그대로 따라가게 된다.
버튼을 클릭할 때마다 isTimer 값이 변경되므로 producer 영역이 다시 시작되게 되며, 이전에 수행 중이던 작업이 있다면 awaitDispose block을 통해 cancel이 호출되게 된다.
isTimer가 true일 때, 1초당 value를 1씩 증가하게 되므로 isTimer가 true일 때만 Text 영역에 있는 Time : $timer의 값이 변경된다.
상당히 복잡하다.
필자도 업무를 진행하면서 produceState를 사용한 적은 없다.
하지만 생각해 보면 produceState를 사용하면 더 짧고 깔끔하게 구현할 수 있는 다양한 작업들을 풀어서 복잡하게 구현한 부분이 있다고 생각이 들기는 한다.
A라는 값이 변경되었을 때, 특정한 동작을 수행한 후 B라는 변수에 데이터를 반환해야 한다.라는 작업이 수행될 때 produceState를 사용하면 쉽게 구현이 가능할 것으로 보인다.
마지막으로는 derivedStateOf이다.
@StateFactoryMarker
fun <T> derivedStateOf(
calculation: () -> T,
): State<T> = DerivedSnapshotState(calculation, null)
derivedStateOf에 매개변수로 들어있는 람다 함수의 이름만 봐도 어떤 동작을 하는지 알 것 같다.
특정 데이터를 계산한 결과를 반환해 주는 snapshotState로 보인다.
바로 예제를 통해 어떻게 사용되는지 알아보자.
val derivedStateCheckData = remember(timer) {
derivedStateOf { timer > 0 && timer % 2 != 0 }
}
위에서 사용했던 timer를 그대로 사용하였다.
timer는 isTimer의 값이 true일 때 1초에 1의 값이 증가하는 int 타입의 변수이다.
그렇기 때문에, derivedStateCheckData에는 timer가 0보다 큰 상태에서, 2초에 한 번씩 true를 반환하게 되는 값이다.
즉, 관찰하고 있는 A라는 변수(timer)의 데이터가 변경되었을 때, derivedStateOf block 안에서 연산한 결과 값을 derivedStateCheckData의 값에 반환해서 저장한다.
이때, 기존에 사용하던 것과 달리 관찰하고 있는 변수와 해당 변수에서 저장되는 데이터의 타입은 일치할 필요는 없다.
이렇게 보았을 때, derivedStateOf도 produceState와 비슷한 동작을 하는 것으로 보인다.
하지만 내부적으로 동작하는 것들만 보아도 이 두 가지 API에서는 큰 차이를 보이고 있기 때문에 필요에 따라 이 두가지 기능을 선택해서 사용하면 될 것으로 보인다.
이것으로 2년 전 Compose를 처음 공부할 때 작성했던 것들을 책 내용 기반이 아닌, 사용해 본 경험을 기반으로 작성을 해보았다.
근본적인 내용은 크게 달라진 것이 없지만, 책의 개념 설명과 같은 범주에서 실제로 어떻게 사용되고 있는지를 기반으로 작성해 보고자 노력했다.
물론, 2년이 지난 지금 다시 보아도 이해가 잘 안 되는 부분도 있고 자주 사용하지 않는 API도 좀 된다.
익숙하지 않기 때문에, 다른 방법으로 구현하는 것이 생각하기가 쉽기 때문에 사용하지 않았던 것들이 보였고, 이번 글을 작성하면서 다시 되돌아보니, 여러 가지 Side Effect에 관련된 API를 다시 상기할 수 있었다.
떠오르지 않아서 사용하고 있지 않은 것들이기 때문에, 기회가 된다면 실무에서 사용하면서 익숙해짐으로써 보다 compose스럽게 코드를 짤 수 있는 연습을 해야겠다.
해당 게시글에 사용한 예제는 Github에 올려두었다.
https://github.com/HeeGyeong/ComposeSample
GitHub - HeeGyeong/ComposeSample: This project provides various examples needed to actually use Jetpack Compose.
This project provides various examples needed to actually use Jetpack Compose. - HeeGyeong/ComposeSample
github.com

